Self-Defined Text-dependent Wake-Up-Words
Speaker Recognition System
Abstract:
In recent years, wake-up-words (WUW) technology is highly
developed in some speaker recognition system. It is the progress of verifying a person's claimed identity
from their voice characteristics, and can be efficiently deployed in some consumer applications. In this paper,
we proposed a self-defined text-dependent wake-up-words (WUW) speaker recognition system and its implementation.
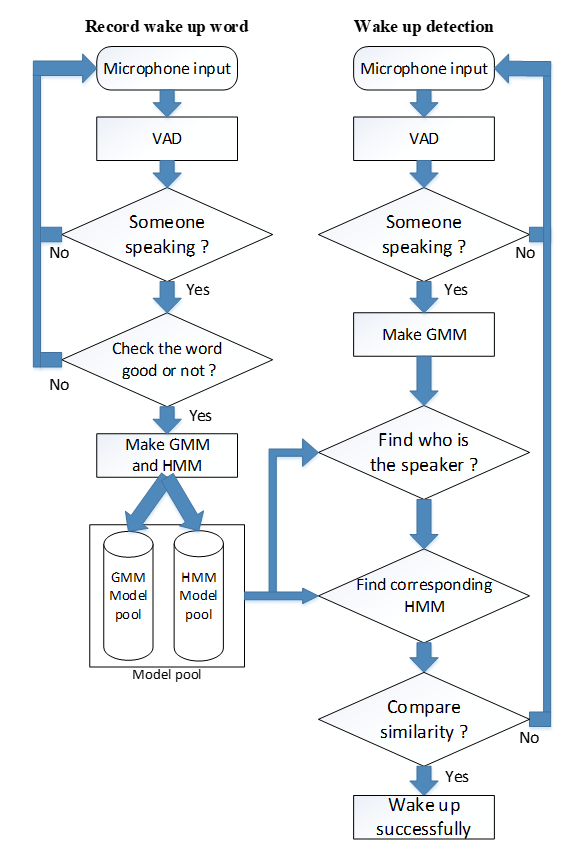
The whole system is divided into two phases: training phase and testing phase. In the training phase, a wake-up word
by language is recorded, and the voice segment is cut out by using Voice Activity Detection (VAD). Then we use the
Mel-Frequency Cepstral Coefficients (MFCC) as the pre-processing to extract the speech features. After obtaining the
speech features, we use Gaussian Mixture Model (GMM) and Hidden Markov Model (HMM) simultaneously for training. In the
testing phase, we build GMM and HMM continuously and use the Levenshtein Distance (LD) to calculate the differences of
the state sequences between the dataset and the unknown speech input. If the unknown speech input passes the threshold,
then it means a wake-up event is derived. The experimental results show that the average accuracy is 93.31 %, 82.42% and
3.38 % in 10dB, 5dB and 0dB of Signal Noise Ratio (SNR) respectively. The CPU and memory usage of entire system is around 7
57 MIPS and 40MB respectively.
System overflow:
Proposed system:

Implementation Results:


Made
by �q����