GMM�y�̿��ѷf�tMFCC�w��]�p
Abstract:
In recent years, speaker verification has been extensively explored and has significantly
improved its effectiveness. The proposed speaker verification system includes two phases: enrollment and verification. In the
enrollment phase, the speaker has to provide appropriate speech, such as continuous number strings, sentences, or phrases for
building the speakers�� models in the system. In the verification phase, the verified speech is substituted into the enrolled
speaker models, and the similarity between the speech and the models is used to discriminate. We further design the whole system
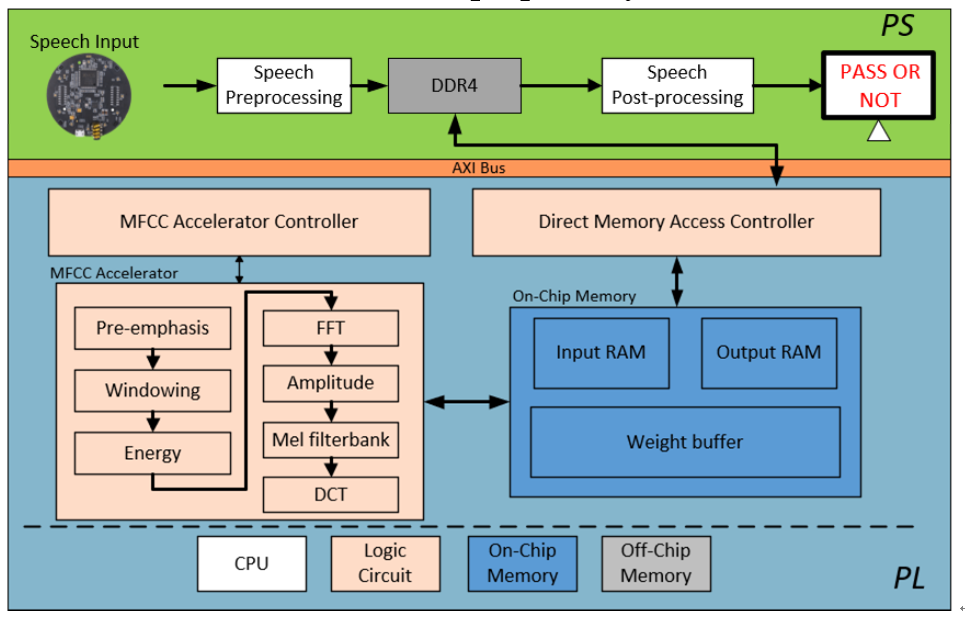
in a system-on-a-chip (SoC). We focus on the Mel-frequency cepstral coefficients (MFCCs) pre-processing module on FPGA and implement
the lightweight the post-processing models such as Gaussian Mixture Model (GMM) and Hidden Markov Model (HMM) in software.
Feature:
qA piece of speech data can be processed in 53.6ms to meet the real-time way.
qThe proposed speaker verification system has an 93.3% accuracy rate.
qThe overall architecture consumes only 4.26W on Xilinx ZCU104 with a 200 MHz operating frequency.
The speaker verification system flowchart:

Overall architecture of the proposed system on MPSoC:
Implementation Results:

Demo:
Train
Test
Made
by �����