Design and Implementation of Low-Power, Energy-Efficient Neural Network Training Hardware
Accelerators Based on Brain Floating-Point Computing and Sparsity Aware
�K�n:
�b����s���A�ڭ̴��X�@�Ө㦳���į�B���F���ʪ��V�m�B�z���A�ڭ̧⥦�R�W��EESA�C
��ij���V�m�B�z���㦳�C�\�ӡB���]�R�q�M����ĵ��S�I�CEESA�Q�ί��g���E�����}���ʨӴ�ְO����X�ݪ����ƥH�ΰO�����x�s���Ŷ��A
�H��{���Ī��V�m�[�t���C�Ҵ��X���B�z���ϥΤF�@�طs�o���i���s�t�m���p��[�c�A�b���V�Ǽ��]FP�^�H�ΤϦV�Ǽ��]BP�^�L�{���O�����ʯ�C
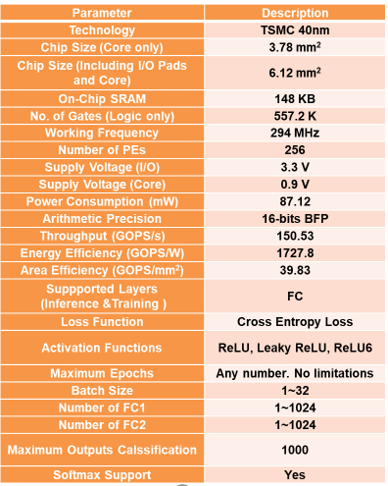
�ӳB�z���ĥΥx�n�q40 nm�u���N��{�A��B�檺�ާ@�W�v��294 MHz�A��Ӵ������\�Ӭ�87.12 mW�A�ϥΪ��֤߹q����0.9 V�C�b��Ӵ������A
�ڭ̨ϥ�16�줸�����B�I�B���榡�ӧ����Ҧ���ƪ��ƭȹB��A�̲ӳB�z����{�F1.72 TOPS/W������Ī��{�C
��s�^�m:
q
��ij���B�z���ϥ�
16-bits brain floating point
�o�طs�o���B���榡�C
q�q�L�ϥΤ@�ӷs�o���i���s�t�m���B�z����(PE)�[�c�A�ӧ������s���h���V�m�α��z���q�C
q ��ij���B�z���Q�ί��g�����}���ʤε��X�F����Ǵ��X���u�ưO����X�ݤ�k�A�Ӵ�֥��V�Ǽ��ΤϦV�Ǽ��B��һݭn���O����Ŷ��ΰO����X�ݪ����ơA�Ӵ�����IJv�C
q �Ҵ��X���w��]�p�b�x�n�q40nm�u���N����{�A�b294MHz�M0.9V���֤߹q���U�A��{�F87.12mW���\�Ӥ�1.72TOPS/W����IJv�C
Proposed Overall Architecture:

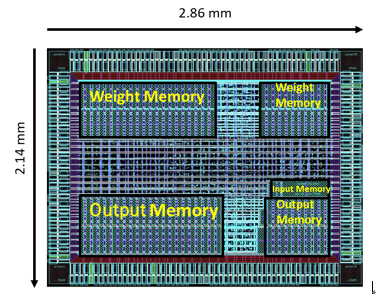
Implementation Results:
Made
by �L�w��