A Reconfigurable Hardware Architecture for Spatial Temporal Graph Convolution Network
Abstract:
Graph Convolutional Networks (GCNs) are well-suited for human action recognition using skeleton data,
as they handle non-Euclidean structures like human joints and avoid issues with environmental noise affecting RGB images. However,
GCNs often suffer from high latency and low power efficiency on CPU and GPU platforms due to computational complexity.
To address this, we propose a parallel and scalable architecture for Spatial-Temporal GCN (ST-GCN), commonly used in action recognition.
Our design, implemented on ASIC and FPGA, reduces latency by 39.5% and improves power efficiency by 1.78x compared to existing hardware designs.
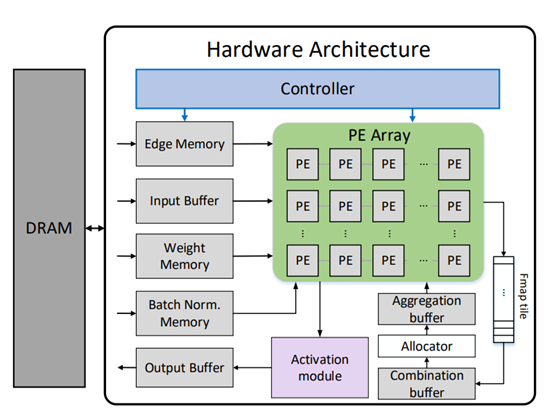
Hardware architecture: The figure shows our overall architecture. Due to SRAM resource limitations, we cannot store all inputs and weights required for the computation in the accelerator,
so the data are stored in the DRAM and then batch transferred to the accelerator for the computation. The accelerator contains several SRAMs to store weights, edge information, and batch normalization parameters.
Our computation unit uses a unified PE design but can be separated into two parts while computing spatial convolution: combination PEs and aggregation PEs.
First, the controller will receive the layer information and allocate a different amount of PEs for the combination and aggregation process.
For temporal convolution, the unified PEs are connected to each other serially for data reuse. Then, the weight data, edge information, and batch normalization parameters are transmitted from the off-chip DRAM.
Finally, the input feature maps will be sent into the architecture and the results will be computed simultaneously.
Before delivering the output feature maps to the off-chip DRAM, the data will go through the activation module which is set as a Rectified Linear Unit (ReLU) in the ST-GCN network.
The overall architecture
Made
by ���l��