A High-Performance Neural Network SoC for End-to-End Speaker Verification
Abstract:
The use of the neural network to recognize speakers' identity from their speech sounds has become popular in the last few years.
Among these methods, the x-vector extractor performs more noise-canceling and usually has higher accuracy than the previous method, such as the Gaussian mixture model (GMM) and the support vector machine (SVM).
This paper presents a system-on-chip (SoC) composed of a RISC-V CPU and a neural network accelerator module for x-vector-based speaker verification (SV).
To ensure real-time latency and enable the implementation of the system on edge devices, this work employs three steps for processing x-vector including: size reduction, pruning, and compression.
We are dedicated to optimizing the data flow with sparsity. Compared with the conventional sparse matrix compression method compressed sparse row (CSR), we propose the binary pointer compressed sparse row (BPCSR) method which significantly improves the latency and avoids the load balancing issue in each PEs.
We further design the neural network accelerator module that stores the compressed parameters and computes the x-vector extractor while the RISC-V CPU processes the rest of the calculations such as feature extraction and the classifier.
The system was tested on the Voxceleb dataset, containing 1251 test speakers, and achieved over 95% accuracy. Lastly, we synthesized the chip with TSMC 90 nm technology.
It presents 15.5 mm2 in the area and 97.88 mW for real-time identification.
Artitechture: The entire SoC architecture is represented in Fig. 1. The left part of the AHB bus decoder illustrates the CPU system, and the other side is the neural network accelerator module.
After loading the necessary instructions and data, the CPU starts to process the program.
When the CPU requires data, it sends the address to the bus decoder to decode the corresponding location based on the defined memory map to read the data.
Firstly, the CPU processes the FBANK feature extraction. When the CPU completes FBANK and the result of each frame has been saved to the global buffer (GB), the CPU enables the status register to wake up the neural network module.
Meanwhile, the CPU is set to wait for interrupt (WFI) mode, i.e., the system temporarily shutdowns the CPU and cut-off the core clock until the interrupt occurs.
Since the CPU completes the feature extraction, the authority of GB access is handed over from the CPU to the neural network module by the status register.
During the computing in the neural network module, the module accesses the data from GB, and the processed data overwrites the original data. When the neural network module computations are finished, the module disables the status register to generate the interrupt.
Since the CPU wakes up after an interrupt, the authority of GB access is returned to the CPU. The CPU copies the x-vector extractor from GB to other RAM. Lastly, the CPU computes the PLDA score with previously calculated x-vectors.
The output of the SV can be represented in multiple ways by peripheral IO. For example, we can exploit the General Purpose input/output (GPIO) to directly activate some of the back-end devices or print the result in text form to the target terminal by Universal Asynchronous receiver/transmitter (UART). Therefore, the SV system shows better flexibility.
Fig 1�GAn overview of the proposed SV SoC.
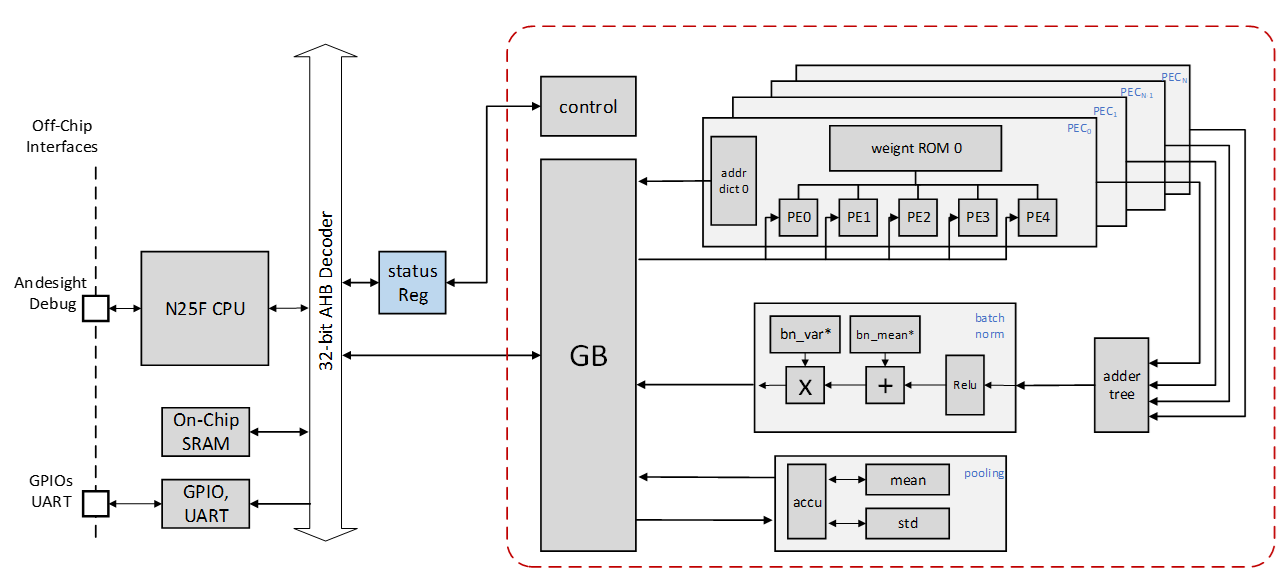

Fig 2:The proposed neural network module architecture and dataflow.
Made
by ���s��